





Всех приветствую! Сегодня будет спонтанная статья по мотивам осуществленного отладочного процесса ) Итак, предыстория такова...
У многих стали возникать сбои при использовании проекта для Modbus Slave, причем поведение было практически на 100 процентов идентичное. Повторяемость идеальная, казалось бы, бери да решай, но проблема долгое время была в том, что у меня все работало четко... При этом опять же из статистики было абсолютно очевидно, что какой-то баг существует точно, но меня он решил обойти стороной, до поры до времени...
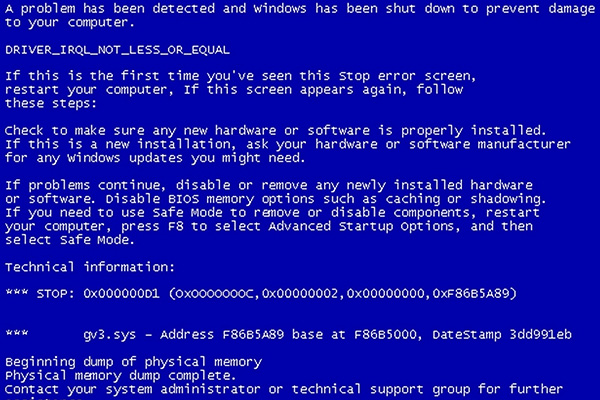
И тут ключевой вклад внес Алексей, поскольку он акцентировал внимание на том, что сбой появляется при работе с Modbus в IAR. "Хмм" подумал я, и действительно при сборке в IAR'е у меня наипрекраснейшим образом воспроизвелась та же самая проблема 👍 Собственно, заключается она в том, что через некоторое время обмен данными останавливается окончательно и бесповоротно с ошибкой timeout error:
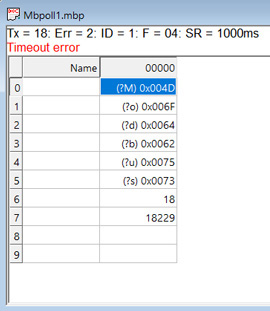
Я сразу же создал два абсолютно одинаковых проекта, за той лишь разницей, что один под IAR, а второй под STM32CubeIDE. Ну и да, второе отличие между этими проектами было такое, что CubeIDE Edition работала стабильно, а IAR'овский вариант крашился через несколько десятков успешных запросов. Причем единственным вариантом вернуть работоспособность был только перезапуск программы. В STM32CubeIDE при этом спокойно работало несколько часов без проблем, далее мое терпение истекало:
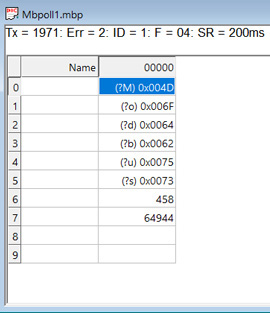
А, как видите, альтернативный вариант проекта зависал уже при 18 запросах (скриншот выше). Но самое главное было осуществлено успешно, а именно воспроизведение проблемы - когда есть стабильная повторяемость, то все становится намного радужнее )
И первый тест для улучшения представления о происходящем - изменить период опроса Slave, допустим с 1000 мс до 200 мс. По итогу результат тот же. При этом есть строгая корреляция, меньше период опроса, меньшее время проходит до зависания. Отсюда сразу же очевидный вывод - все завязано на количестве запросов, а не на их частоте и чем-то ином. В принципе, даже с настройками периферии - baudrate USART'а, периодом таймера и прочим - возиться смысла нет, поскольку они идентичны в обоих проектах, результат же работы диаметрально противоположный.
Итак, промежуточный итог: один и тот же проект в IAR не работает, в CubeIDE - работает, крах наступает через определенное количество запросов. И все это не то что намекает, а просто кричит, что проблема кроется в неправильной работе с памятью на каком-то этапе. На каком этапе неизвестно и в чем неправильность - тоже, тем не менее начало отличное 👌
Далее следует этап осмысленного изменения настроек IAR'а, которое с каждым вариантом становится все менее осмысленным, а под конец превращается в случайное выставление/снятие галочек в настройках проекта без малейших раздумий. Если что, это не рекомендация ) Результата данный процесс не принес, да особо и не ожидалось.
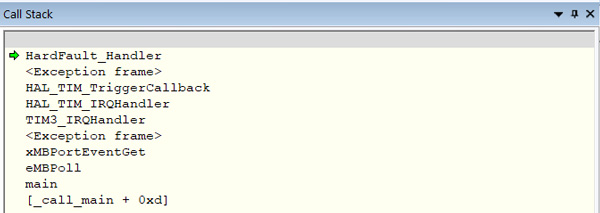
Возвращаемся к логичной деятельности. В момент, когда пакеты перестают проходить, программа оказывается в случайных местах и с разным результатом, например, классика, HardFault:
Imprecise data access:

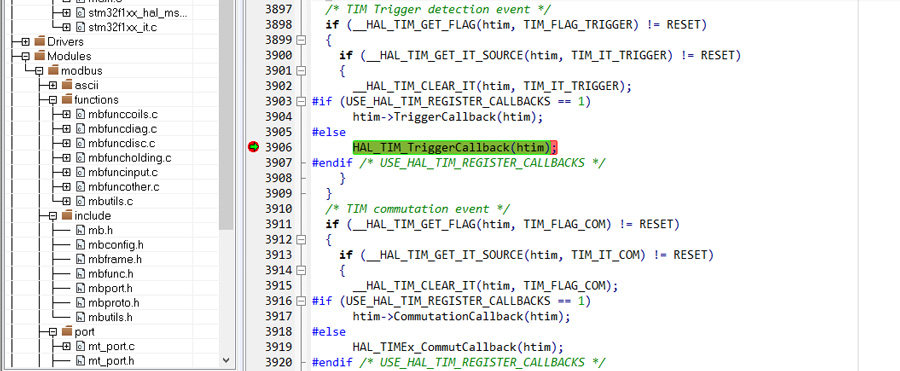
Все это еще более явно, хотя куда уже более, намекает о том, что корень зла в неправильном обращении к некой памяти. Остается найти место и причину. Дизассемблер и Call Stack особо новой информации не дали, но понаблюдав за процессами, протекающими после нарушения нормальной работы, мне бросилось в глаза, что обработчик прерывания заносит в места, в которые он априори попадать не должен, к примеру на callback HAL_TIM_TriggerCallback(htim), как раз этот случай на скриншоте.
Подозрительным является то, что перед этим следует проверка регистра DIER (if (__HAL_TIM_GET_IT_SOURCE(htim, TIM_IT_TRIGGER) != RESET)), в котором указано, какие прерывания включены, а какие нет. А логика и алгоритм работы программы не оставляют сомнений, что данные события не используются, налицо несоответствие, проверяем регистры таймера и там находим по большому счету случайный набор битов.
Ответ на вопрос "почему" находится очень просто. Сравним HAL'овский handler TIM_HandleTypeDef htim3 в начале работы программы и после ее краха. До:
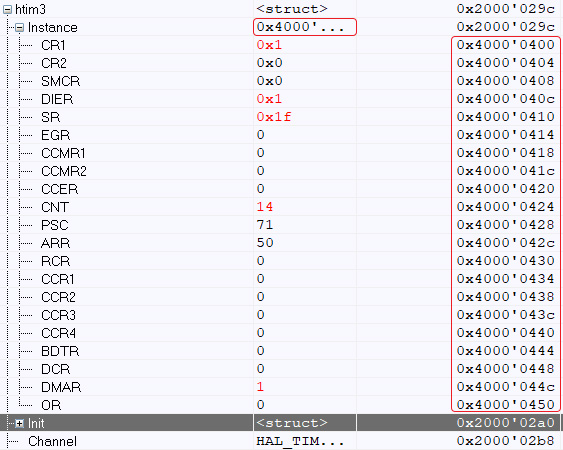
После:
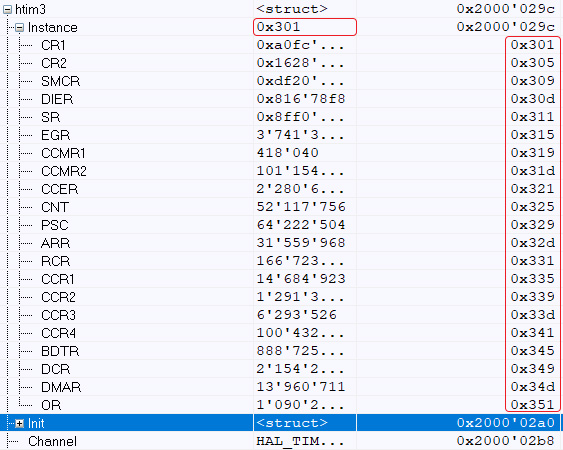
Вывод снова прост - в какой-то момент происходит запись не по тому адресу, что затрагивает элементы, которые затрагивать не должно. Это и объясняет изначальный эффект возникновения сбоев в одной IDE при отсутствии аналогичных в другой.
Ставим Data Breakpoint на htim3.Instance, причем нас интересует именно момент, когда происходит запись:
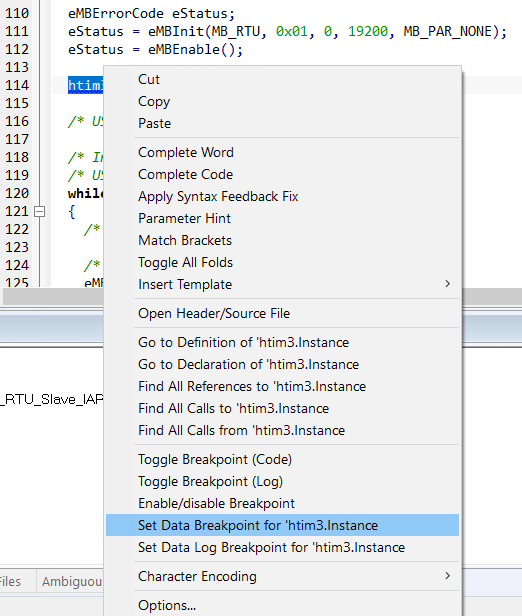
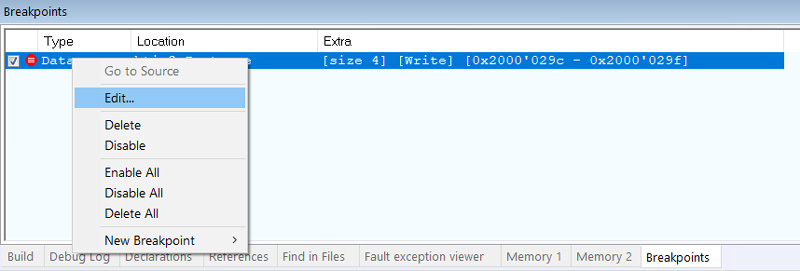
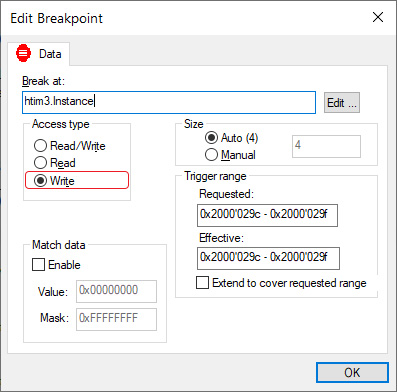
Пару раз break очевидно сработает при инициализации периферии, а дальше просто ждем, когда процесс отладки выведет нас к финишу ) И вот он финал, запись в htim3.Instance происходит здесь:
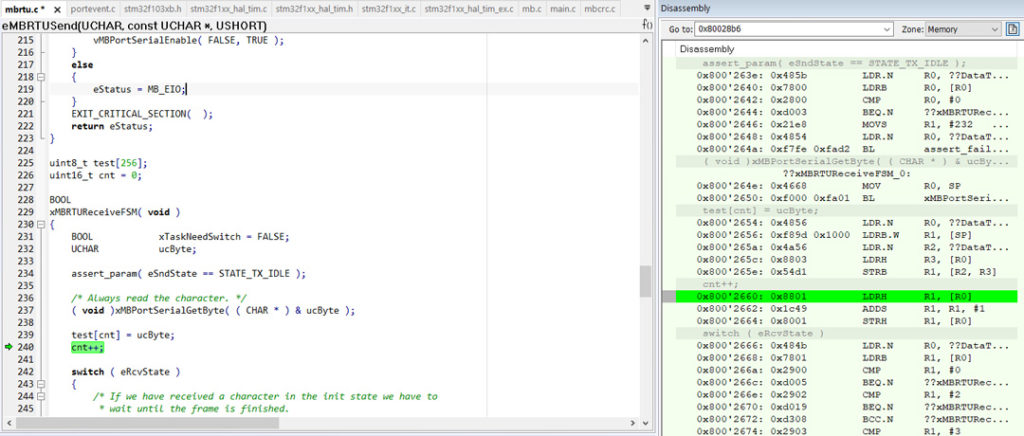
uint8_t test[256];
uint16_t cnt = 0;
BOOL
xMBRTUReceiveFSM( void )
{
BOOL xTaskNeedSwitch = FALSE;
UCHAR ucByte;
assert_param( eSndState == STATE_TX_IDLE );
/* Always read the character. */
( void )xMBPortSerialGetByte( ( CHAR * ) & ucByte );
test[cnt] = ucByte;
cnt++;
// ... ... ...

Практически классика - кто-то добавил отладочный код, видимо, чтобы посмотреть принятые байты. Ну и, поскольку, это "чисто для отладки на минутку", то объявлен массив на 256 элементов, куда и заносятся эти данные. Далее дело техники - код не удален, проходит время, буфер переполняется и запись ведется в память, занимаемую абсолютно другими ресурсами. Фееричный по свой глупости баг, но всякое бывает, даже более того - бывает и не такое )
Резюме - мы получили в свое распоряжение интересную задачу по идентификации проблемы, а также исправленный работоспособный проект на выходе, чего еще желать 👍
На этом и заканчиваем, спасибо всем, кто сигнализировал об этой проблеме, причем с дополнительной информацией, которая также помогла в решении, до новых статей 🤝




А почему в CubeIDE это не проявлялось?
Не было ничего критичного в памяти после тестового буфера размещено.
Просто нефиг переменную индекса делать было uint16_t. Было бы uint8_t и все бы было нормально.
Это смотря как оценивать. Было бы uint8_t - не обнаружилось бы.
Согласен! Но и не мешало бы.
В этом плане да, именно так )